Swarm 是使用 SwarmKit 构建的 Docker 引擎内置(原生)的集群管理和编排工具。其主要作用是把若干台 Docker 主机抽象为一个整体,并且通过一个入口统一管理这些 Docker 主机上的各种 Docker 资源。Swarm 和 Kubernetes 比较类似,但是更加轻量,具有的功能也较 kubernetes 更少一些。
一、简介
1.1 swarm 是什么
Docker v1.12 是一个非常重要的版本,Docker 重新实现了集群的编排方式。在此之前,提供集群功能的 Docker Swarm 是一个单独的软件,而且依赖外部数据库(比如 Consul、etcd 或 Zookeeper)。从 v1.12 开始,Docker Swarm 的功能已经完全与 Docker Engine 集成,要管理集群,只需要启动 Swarm Mode。安装好 Docker,Swarm 就已经在那里了,服务发现也在那里了(不需要安装 Consul 等外部数据库)。
Docker 的 Swarm (集群)模式,集成很多工具和特性,比如:跨主机上快速部署服务,服务的快速扩展,集群的管理整合到 docker 引擎,这意味着可以不可以不使用第三方管理工具。分散设计,声明式的服务模型,可扩展,状态协调处理,多主机网络,分布式的服务发现,负载均衡,滚动更新,安全(通信的加密)等等。
1.2 swarm 基本概念
1.2.1 节点
运行 Docker 的主机可以主动初始化一个 Swarm 集群或者加入一个已存在的 Swarm 集群,这样这个运行 Docker 的主机就成为一个 Swarm 集群的节点 (node) 。
节点分为管理 (manager) 节点和工作 (worker) 节点。
管理节点用于 Swarm 集群的管理,docker swarm 命令基本只能在管理节点执行(节点退出集群命令 docker swarm leave 可以在工作节点执行)。一个 Swarm 集群可以有多个管理节点,但只有一个管理节点可以成为 leader,leader 通过 raft 协议实现。
工作节点是任务执行节点,管理节点将服务 (service) 下发至工作节点执行。管理节点默认也作为工作节点。也可以通过配置让服务只运行在管理节点。
Docker 官网的这张图片形象的展示了集群中管理节点与工作节点的关系。
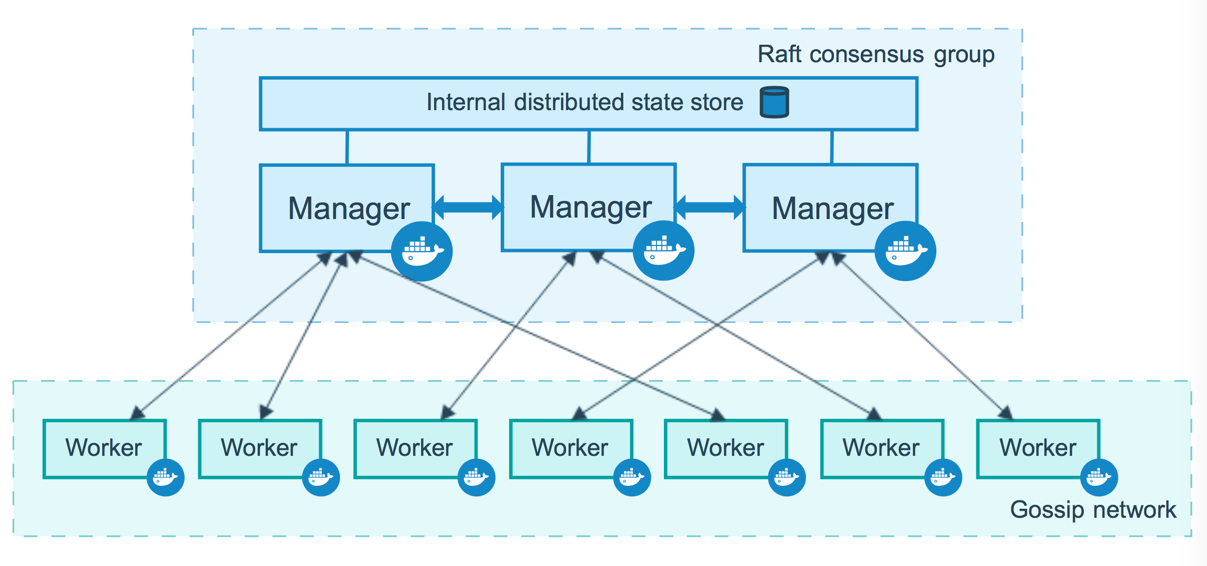
1.2.2 服务和任务
任务 (Task)是 Swarm 中的最小的调度单位,目前来说就是一个单一的容器。
服务 (Services) 是指一组任务的集合,服务定义了任务的属性。服务有两种模式:
- replicated services 按照一定规则在各个工作节点上运行指定个数的任务。
- global services 每个工作节点上运行一个任务
两种模式通过 docker service create 的 –mode 参数指定。
1.2.3 负载均衡
manager 群集管理器使用 ingress load balancing 来对外公开群集提供的服务。manager 可以自动为 PublishedPort 分配服务,也可以手动配置。如果未指定端口,则swarm管理器会为服务分配30000-32767 范围内的端口。
外部组件(例如云负载平衡器)可以访问群集中任何节点的 PublishedPort 上的服务,无论该节点当前是否正在运行该服务的任务。群集中的所有节点都将入口连接到正在运行的任务实例。
Swarm 模式有一个内部 DNS 组件,可以自动为 swarm 中的每个服务分配一个 DNS 条目。群集管理器使用内部负载平衡来根据服务的DNS名称在群集内的服务之间分发请求。
1.3 swarm 特性
-
集群管理与 Docker Engine 集成: 使用 Docker Engine CLI 来创建一个你能部署应用服务到 Docker Engine 的 swarm。你不需要其他编排软件来创建或管理 swarm。
-
分散式设计:Docker Engine 不是在部署时处理节点角色之间的差异,而是在运行时扮演自己角色。你可以使用 Docker Engine 部署两种类型的节点,管理器和 worker。这意味着你可以从单个磁盘映像构建整个- swarm。
-
声明性服务模型: Docker Engine 使用声明性方法来定义应用程序堆栈中各种服务的所需状态。例如,你可以描述由消息队列服务和数据库后端的 Web 前端服务组成的应用程序。
-
伸缩性:对于每个服务,你可以声明要运行的任务数。当你向上或向下缩放时,swarm 管理器通过添加或删除任务来自动适应,以保持所需状态。
-
期望的状态协调:swarm 管理器节点持续监控群集状态,并调整你描述的期望状态与实际状态之间的任何差异。 例如,如果设置运行一个10个副本容器的服务,这时 worker 机器托管其中的两个副本崩溃,管理器则- 将创建两个新副本以替换已崩溃的副本。 swarm 管理器将新副本分配给正在运行和可用的 worker。
-
多主机网络:你可以为服务指定覆盖网络(overlay network)。 当swarm管理器初始化或更新应用程序时,它会自动为容器在覆盖网络(overlay network)上分配地址。
-
服务发现:Swarm 管理器节点为 swarm 中的每个服务分配唯一的 DNS 名称,并负载平衡运行中的容器。 你可以通过嵌入在 swarm 中的 DNS 服务器查询在 swarm 中运行中的每个容器。
-
负载平衡:你可以将服务的端口暴露给外部的负载均衡器。 在内部,swarm 允许你指定如何在节点之间分发服务容器。
-
安全通信:swarm 中的每个节点强制执行 TLS 相互验证和加密,以保护其自身与所有其他节点之间的通信。 你可以选择使用自签名根证书或来自自定义根 CA 的证书。
-
滚动更新:在上线新功能期间,你可以增量地应用服务更新到节点。 swarm 管理器允许你控制将服务部署到不同节点集之间的延迟。 如果出现任何问题,你可以将任务回滚到服务的先前版本。
二、架构分析
2.1 基本架构
Docker Swarm 提供了基本的集群能力,能够使多个 Docker Engine 组合成一个 group,提供多容器服务。Swarm 使用标准的 Docker API,启动容器可以直接使用 docker run 命令。Swarm 更核心的则是关注如何选择一个主机并在其上启动容器,最终运行服务。 Docker Swarm 基本架构,如下图所示:
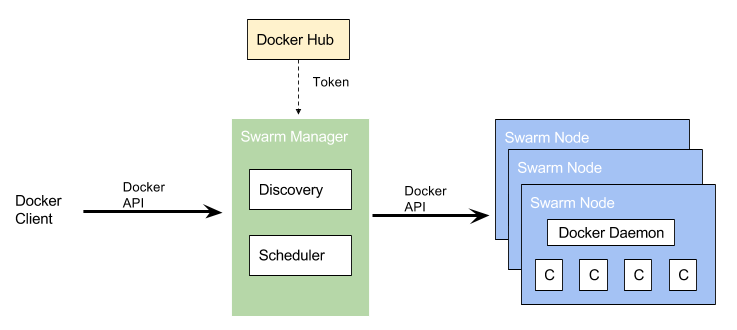
如上图所示,Swarm Node 表示加入 Swarm 集群中的一个 Docker Engine 实例,基于该 Docker Engine 可以创建并管理多个 Docker 容器。其中,最开始创建 Swarm 集群的时候,Swarm Manager便是集群中的第一个 Swarm Node。在所有的 Node 中,又根据其职能划分为 Manager Node 和 Worker Node。
2.1 Manager Node
Manger 节点,顾名思义,是进行 Swarm 集群的管理工作的,它的管理工作集中在如下部分,
- 维护一个集群的状态;
- 对 Services 进行调度;
- 为 Swarm 提供外部可调用的 API 接口;
Manager 节点需要时刻维护和保存当前 Swarm 集群中各个节点的一致性状态,这里主要是指各个 Tasks 的执行的状态和其它节点的状态;因为 Swarm 集群是一个典型的分布式集群,在保证一致性上,Manager 节点采用 Raft 协议来保证分布式场景下的数据一致性;
通常为了保证 Manager 节点的高可用,Docker 建议采用奇数个 Manager 节点,这样的话,你可以在 Manager 失败的时候不用关机维护,我们给出如下的建议:
- 3 个 Manager 节点最多可以同时容忍 1 个 Manager 节点失效的情况下保证高可用;
- 5 个 Manager 节点最多可以同时容忍 2 个 Manager 节点失效的情况下保证高可用;
- N 个 Manager 节点最多可以同时容忍 (N−1)/2个 Manager 节点失效的情况下保证高可用;
- Docker 建议最多最多的情况下,使用 7 个 Manager 节点就够了,否则反而会降低集群的性能了。
2.2 Worker Node
Worker Node 接收由 Manager Node 调度并指派的 Task,启动一个 Docker 容器来运行指定的服务,并且 Worker Node 需要向 Manager Node 汇报被指派的 Task 的执行状态。
2.3 更换角色
通过 docker node promote 命令将一个 Worker 节点提升为 Manager 节点。通常情况下,该命令使用在维护的过程中,需要将 Manager 节点占时下线进行维护操作;同样可以使用 docker node demote 将某个 manager 节点降级为 worker 节点。
2.2 设计架构
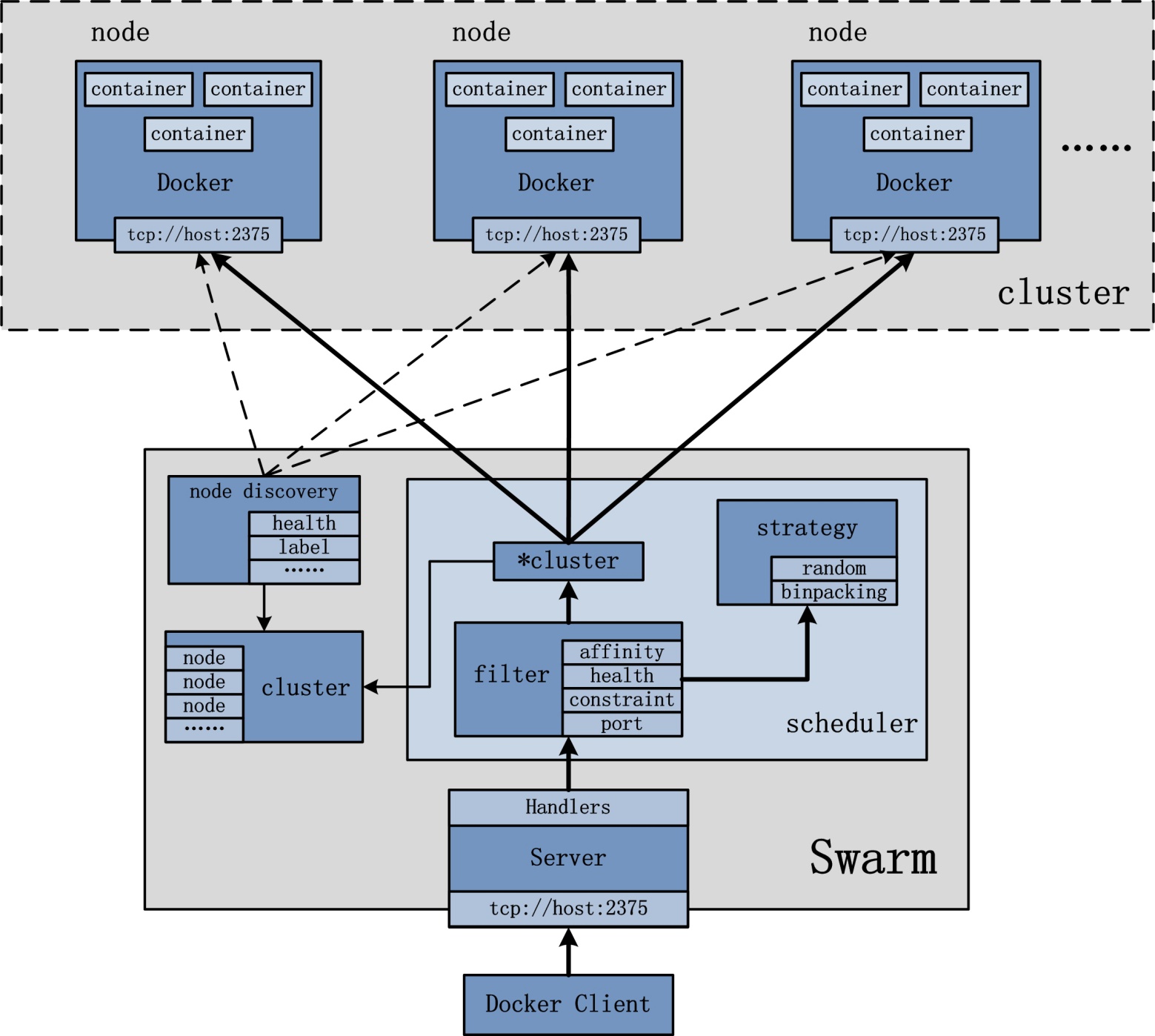
从前文可知, Swarm 集群的管理工作是由 manager 节点实现。如上图所示,manager 节点实现的功能主要包括:node discovery,scheduler,cluster 管理等。同时,为了保证 Manager 节点的高可用,Manager 节点需要时刻维护和保存当前 Swarm 集群中各个节点的一致性状态。在保证一致性上,Manager 节点采用 Raft 协议来保证分布式场景下的数据一致性;
Docker Swarm 内置了 Raft 一致性算法,可以保证分布式系统的数据保持一致性同步。Etcd, Consul 等高可用键值存储系统也是采用了这种算法。这个算法的作用简单点说就是随时保证集群中有一个Leader,由 Leader 接收数据更新,再同步到其他各个 Follower 节点。在 Swarm 中的作用表现为当一个 Leader 节点 down 掉时,系统会立即选取出另一个 Leader 节点,由于这个节点同步了之前节点的所有数据,所以可以无缝地管理集群。
Raft 的详细解释可以参考《The Secret Lives of Data–Raft: Understandable Distributed Consensus》。
2.2.1 跨主机容器通信
Docker Swarm 内置的跨主机容器通信方案是 overlay 网络,这是一个基于 vxlan 协议的网络实现。VxLAN 可将二层数据封装到 UDP 进行传输,VxLAN 提供与 VLAN 相同的以太网二层服务,但是拥有更强的扩展性和灵活性。 overlay 通过虚拟出一个子网,让处于不同主机的容器能透明地使用这个子网。所以跨主机的容器通信就变成了在同一个子网下的容器通信,看上去就像是同一主机下的 bridge 网络通信。
为支持容器跨主机通信,Docker 提供了 overlay driver,使用户可以创建基于 VxLAN 的 overlay 网络。其实,docker 会创建一个 bridge 网络 “docker_gwbridge”,为所有连接到 overlay 网络的容器提供访问外网的能力。`docker network inspect docker_gwbridge 查看网络信息。
下面我们讨论下 overlay 网络的具体实现:
docker 会为每个 overlay 网络创建一个独立的 network namespace,其中会有一个 linux bridge br0,endpoint 还是由 veth pair 实现,一端连接到容器中(即 eth0),另一端连接到 namespace 的 br0 上。
br0 除了连接所有的 endpoint,还会连接一个 vxlan 设备,用于与其他 host 建立 vxlan tunnel。容器之间的数据就是通过这个 tunnel 通信的。逻辑网络拓扑结构如图所示:
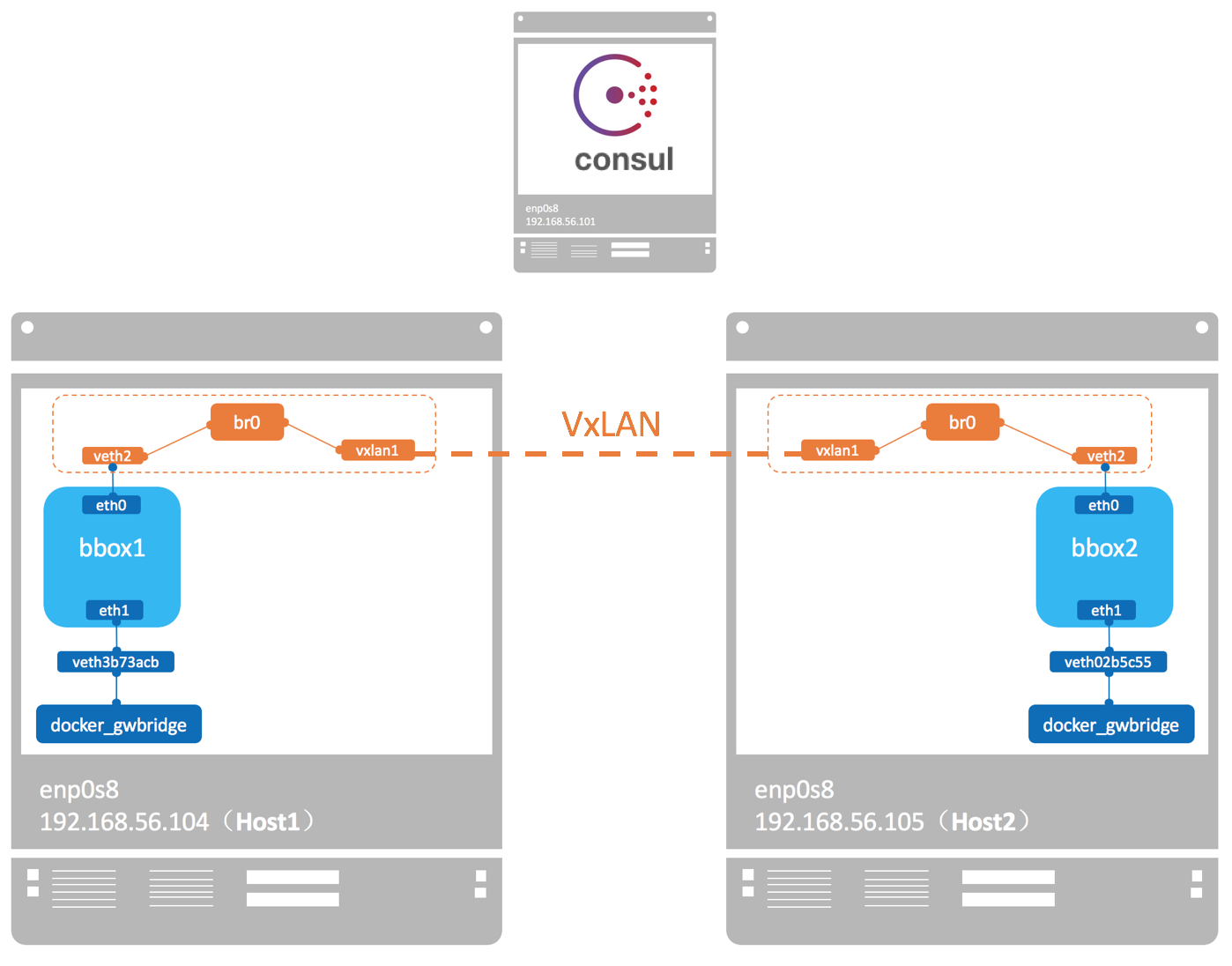
2.2.2 服务发现
docker Swarm mode 下会为每个节点的 docker engine 内置一个 DNS server,各个节点间的 DNS server 通过 control plane 的 gossip 协议互相交互信息。此处 DNS server 用于容器间的服务发现。swarm mode 会为每个 –net= 自定义网络的 service 分配一个 DNS entry。目前必须是自定义网络,比如 overaly。而 bridge 和 routing mesh 的 service,是不会分配 DNS 的。
那么,下面就来详细介绍服务发现的原理。
每个 Docker 容器都有一个 DNS 解析器,它将 DNS 查询转发到 docker engine,该引擎充当 DNS 服务器。docker 引擎收到请求后就会在发出请求的容器所在的所有网络中,检查域名对应的是不是一个容器或者是服务,如果是,docker 引擎就会从存储的 key-value 建值对中查找这个容器名、任务名、或者服务名对应的 IP 地址,并把这个 IP 地址或者是服务的虚拟 IP 地址返回给发起请求的域名解析器。
由上可知,docker 的服务发现的作用范围是网络级别,也就意味着只有在同一个网络上的容器或任务才能利用内嵌的 DNS 服务来相互发现,不在同一个网络里面的服务是不能解析名称的,另外,为了安全和性能只有当一个节点上有容器或任务在某个网络里面时,这个节点才会存储那个网络里面的 DNS 记录。
如果目的容器或服务和源容器不在同一个网络里面,Docker 引擎会把这个 DNS 查询转发到配置的默认 DNS 服务 。
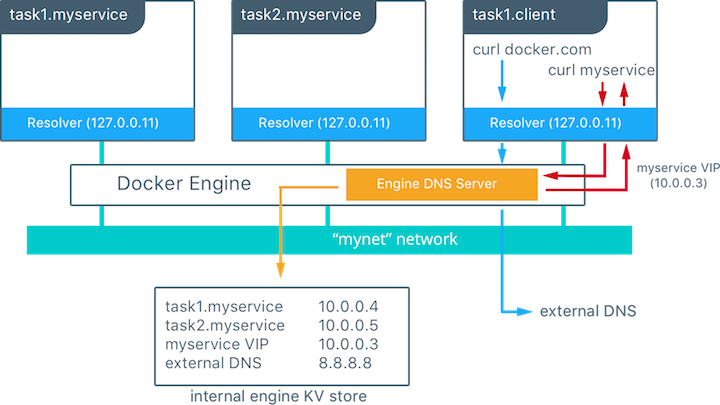
在上面的例子中,总共有两个服务 myservice 和 client,其中 myservice 有两个容器,这两个服务在同一个网里面。在 client 里针对 docker.com 和 myservice 各执行了一个 curl 操作,下面时执行的流程:
- 为了 client 解析 docker.com 和 myservice,DNS 查询进行初始化
- 容器内建的解析器在 127.0.0.11:53 拦截到这个 DNS 查询请求,并把请求转发到 docker 引擎的 DNS 服务
- myservice 被解析成服务对应的虚拟 IP(10.0.0.3),在接下来的内部负载均衡阶段再被解析成一个具体任务的 IP 地址。如果是容器名称这一步直接解析成容器对应的 IP 地址(10.0.0.4或者10.0.0.5)。
- docker.com 在 mynet 网络上不能被解析成服务,所以这个请求被转发到配置好的默认 DNS 服务器(8.8.8.8)上。
2.2.3 负载均衡
负载均衡分为两种:Swarm 集群内的 service 之间的相互访问需要做负载均衡,称为内部负载均衡(Internal LB);从 Swarm 集群外部访问服务的公开端口,也需要做负载均衡,称外部部负载均衡(Exteral LB or Ingress LB)。
- Internal LB
内部负载均衡就是我们在上一段提到的服务发现,集群内部通过 DNS 访问 service 时,Swarm 默认通过 VIP(virtual IP)、iptables、IPVS 转发到某个容器。
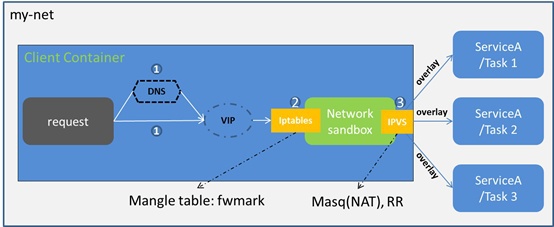
当在 docker swarm 集群模式下创建一个服务时,会自动在服务所属的网络上给服务额外的分配一个虚拟 IP,当解析服务名字时就会返回这个虚拟 IP。对虚拟 IP 的请求会通过 overlay 网络自动的负载到这个服务所有的健康任务上。这个方式也避免了客户端的负载均衡,因为只有单独的一个 IP 会返回到客户端,docker 会处理虚拟 IP 到具体任务的路由,并把请求平均的分配给所有的健康任务。
# 创建 overlay 网络:mynet
$ docker network create -d overlay mynet
a59umzkdj2r0ua7x8jxd84dhr
# 利用 mynet 网络创建 myservice 服务,并复制两份
$ docker service create --network mynet --name myservice --replicas 2 busybox ping localhost
78t5r8cr0f0h6k2c3k7ih4l6f5
# 通过下面的命令查看 myservice 对应的虚拟 IP
$ docker service inspect myservice
...
"VirtualIPs": [
{
"NetworkID": "a59umzkdj2r0ua7x8jxd84dhr",
"Addr": "10.0.0.3/24"
},
]
注:swarm 中服务还有另外一种负载均衡技术可选 DNS round robin (DNS RR) (在创建服务时通过 –endpoint-mode 配置项指定),在 DNSRR 模式下,docker 不再为服务创建 VIP,docker DNS 服务直接利用轮询的策略把服务名称直接解析成一个容器的 IP 地址。
- Exteral LB(Ingress LB 或者 Swarm Mode Routing Mesh)
看名字就知道,这个负载均衡方式和前面提到的 Ingress 网络有关。Swarm 网络要提供对外访问的服务就需要打开公开端口,并映射到宿主机。Ingress LB 就是外部通过公开端口访问集群时做的负载均衡。
当创建或更新一个服务时,你可以利用 –publish 选项把一个服务暴露到外部,在 docker swarm 模式下发布一个端口意味着在集群中的所有节点都会监听这个端口,这时当访问一个监听了端口但是并没有对应服务运行在其上的节点会发生什么呢? 接下来就该我们的路由网(routing mesh)出场了,路由网时 docker1.12 引入的一个新特性,它结合了 IPVS 和 iptables 创建了一个强大的集群范围的 L4 层负载均衡,它使所有节点接收服务暴露端口的请求成为可能。当任意节点接收到针对某个服务暴露的 TCP/UDP 端口的请求时,这个节点会利用预先定义过的 Ingress overlay 网络,把请求转发给服务对应的虚拟 IP。ingress 网络和其他的 overlay 网络一样,只是它的目的是为了转换来自客户端到集群的请求,它也是利用我们前一小节介绍过的基于 VIP 的负载均衡技术。
启动服务后,你可以为应用程序创建外部 DNS 记录,并将其映射到任何或所有 Docker swarm 节点。你无需担心你的容器具体运行在那个节点上,因为有了路由网这个特性后,你的集群看起来就像是单独的一个节点一样。
#在集群中创建一个复制两份的服务,并暴露在 8000 端口
$ docker service create --name app --replicas 2 --network appnet --publish 8000:80 nginx
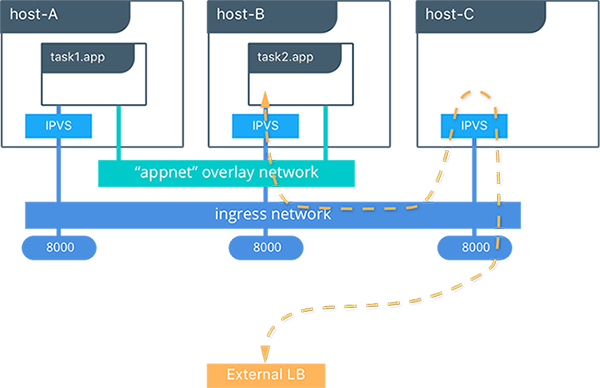
上面这个图表明了路由网是怎么工作的:
- 服务(app)拥有两份复制,并把端口映射到外部端口的 8000
- 路由网在集群中的所有节点上都暴露出 8000
- 外部对服务 app 的请求可以是任意节点,在本例子中外部的负载均衡器将请求转发到了没有 app 服务的主机上
- docker swarm 的 IPVS 利用 ingress overlay 网路将请求重新转发到运行着 app 服务的节点的容器中
注:以上服务发现和负载均衡参考文档 https://success.docker.com/article/ucp-service-discovery
2.3 Services 架构
在微服务部署的过程中,通常将某一个微服务封装为 Service 在 Swarm 中部署执行,通常你需要通过指定容器 image 以及需要在容器中执行的 Commands 来创建你的 Service,除此之外,通常,还需要配置如下选项,
- 指定可以在 Swarm 之外可以被访问的服务端口号 port,
- 指定加入某个 Overlay 网络以便 Service 与 Service 之间可以建立连接并通讯,
- 指定该 Service 所要使用的 CPU 和 内存的大小,
- 指定一个滚动更新的策略 (Rolling Update Policy)
- 指定多少个 Task 的副本 (replicas) 在 Swarm 集群中同时存在
2.3.1 服务和任务
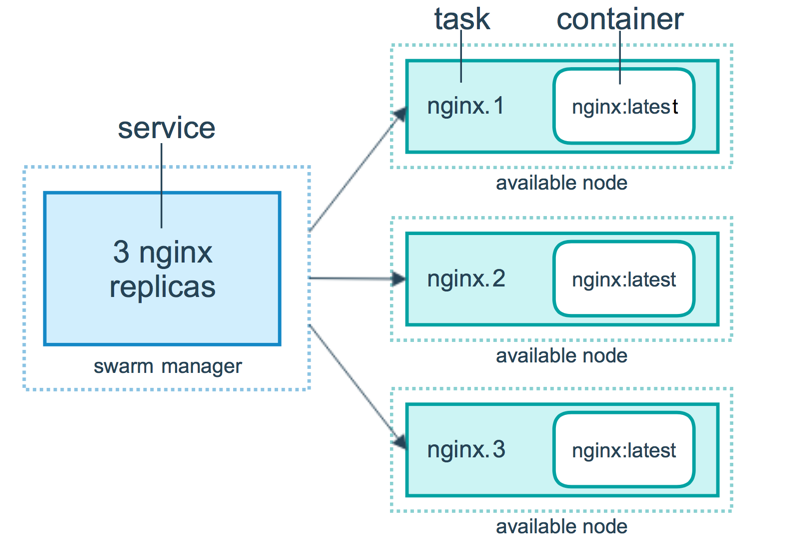
Services,Tasks 和 Containers 之间的关系可以用上面这张图来描述。来看这张图的逻辑,表示用户想要通过 Manager 节点部署一个有 3 个副本的 Nginx 的 Service,Manager 节点接收到用户的 Service definition 后,便开始对该 Service 进行调度,将会在当前可用的Worker(或者Manager )节点中启动相应的 Tasks 以及相关的副本;所以可以看到,Service 实际上是 Task 的定义,而 Task 则是执行在节点上的程序。
Task 是什么呢?其实就是一个 Container,只是,在 Swarm 中,每个 Task 都有自己的名字和编号,如图,比如 nginx.1、nginx.2 和 nginx.3,这些 Container 各自运行在各自的 node 上,当然,一个 node 上可以运行多个 Container;
2.3.2 任务调度
Docker swarm mode 模式的底层技术实际上就是指的是调度器( scheduler )和编排器( orchestrator );下面这张图展示了 Swarm mode 如何从一个 Service 的创建请求并且成功将该 Service 分发到两个 worker 节点上执行的过程。
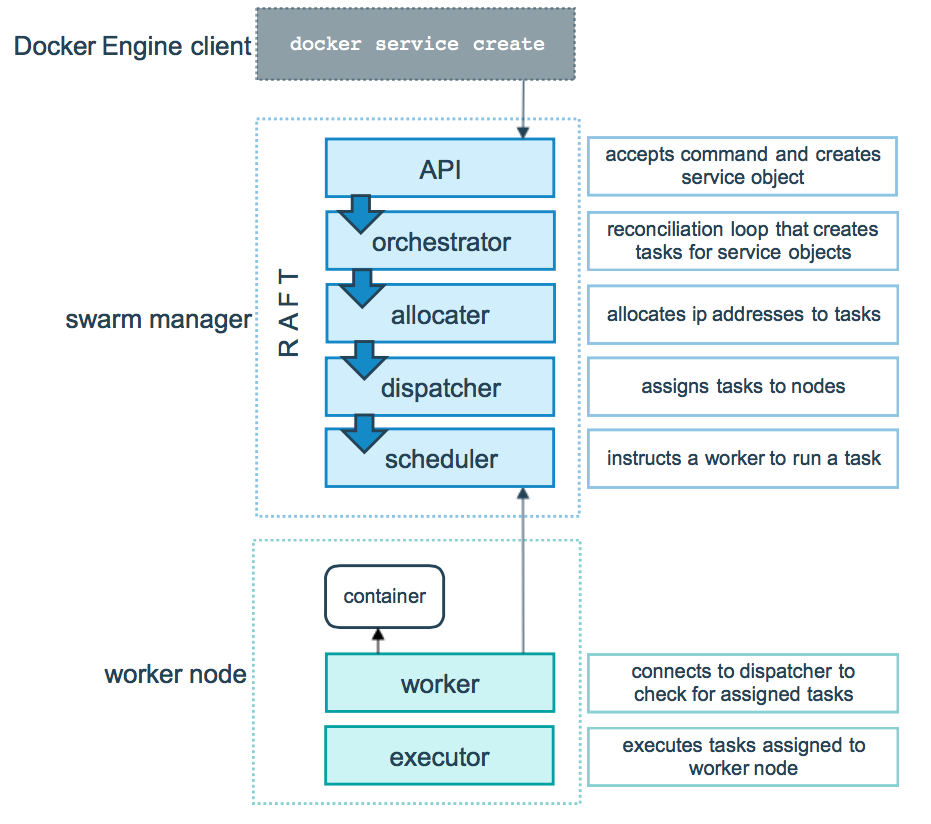
- 首先,看上半部分 Swarm manager
- 用户通过 Docker Engine Client 使用命令 docker service create 提交 Service definition,
- 根据 Service definition 创建相应的 Task,
- 为 Task 分配 IP 地址,
注意,这是分配运行在 Swarm 集群中 Container 的 IP 地址,该 IP 地址最佳的分配地点是在这里,因为 Manager 节点上保存得有最新最全的 Tasks 的状态信息,为了保证不与其他的 Task 分配到相同的 IP,所以在这里就将 IP 地址给初始化好;
-
- 将 Task 分发到 Node 上,可以是 Manager 节点也可以使 Worker 节点,
- 对 Worker 节点进行相应的初始化使得它可以执行 Task
- 接着,看下半部分 Swarm Work
该部分就相对简单许多
-
- 首先连接 manager 的分配器( scheduler)检查该 task
- 验证通过以后,便开始通过 Worker 节点上的执行器( executor )执行;
注意,上述 task 的执行过程是一种单向机制,比如它会按顺序的依次经历 assigned, prepared 和 running 等执行状态,不过在某些特殊情况下,在执行过程中,某个 task 失败了( fails ),编排器( orchestrator )直接将该 task 以及它的 container 给删除掉,然后在其它节点上另外创建并执行该 task;
2.3.3 调度策略
Swarm在scheduler 节点(leader 节点)运行容器的时候,会根据指定的策略来计算最适合运行容器的节点,目前支持的策略有:spread, binpack, random。
-
1)Random 顾名思义,就是随机选择一个 Node 来运行容器,一般用作调试用,spread 和 binpack 策略会根据各个节点的可用的 CPU, RAM 以及正在运 行的容器的数量来计算应该运行容器的节点。
-
2)Spread 在同等条件下,Spread 策略会选择运行容器最少的那台节点来运行新的容器,binpack 策略会选择运行容器最集中的那台机器来运行新的节点。 使用 Spread 策略会使得容器会均衡的分布在集群中的各个节点上运行,一旦一个节点挂掉了只会损失少部分的容器。
-
3)Binpack Binpack 策略最大化的避免容器碎片化,就是说 binpack 策略尽可能的把还未使用的节点留给需要更大空间的容器运行,尽可能的把容器运行在 一个节点上面。(The binpack strategy causes Swarm to optimize for the container which is most packed.)
2.3.4 服务副本与全局服务
Docker Swarm 支持服务的扩容缩容,Swarm 通过 –mode 选项设置服务类型,提供了两种模式:一种是 replicated,我们可以指定服务 Task 的个数(也就是需要创建几个冗余副本),这也是 Swarm 默认使用的服务类型;另一种是 global,这样会在 Swarm 集群的每个 Node 上都创建一个服务。如下图所示(出自 Docker 官网),是一个包含 replicated 和 global 模式的 Swarm 集群:
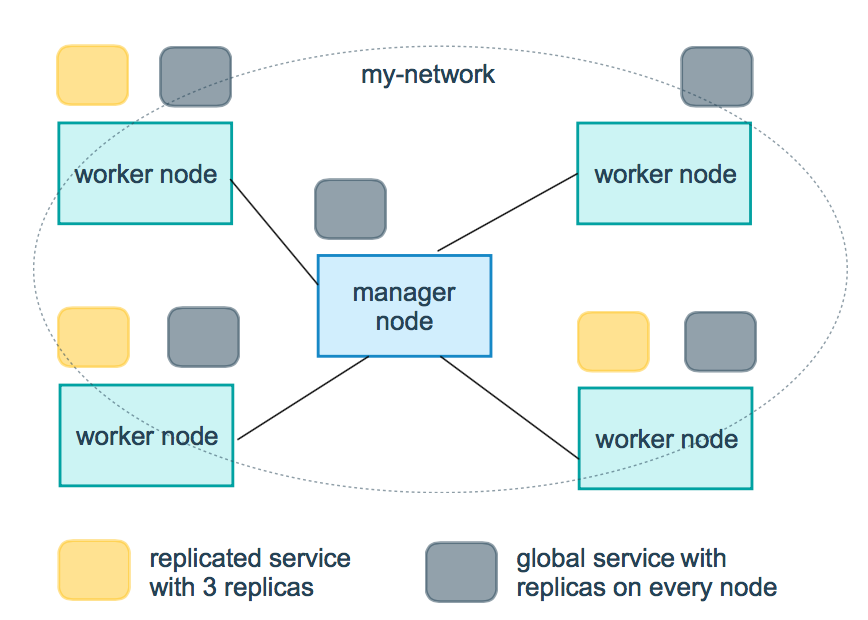
上图中,黄色表示的 replicated 模式下的 Service Replicas,灰色表示 global 模式下 Service 的分布。
在 Swarm mode 下使用 Docker,可以实现部署运行服务、服务扩容缩容、删除服务、滚动更新等功能,下面我们详细说明。
三、集群搭建
3.1 环境配置
虚拟机信息
| IP | hostname | 配置 | 角色 |
|---|---|---|---|
| 172.21.111.56 | swarm01 | 4CPU/6G | Manager |
| 172.21.111.57 | swarm02 | 4CPU/6G | Manager |
| 172.21.111.58 | swarm03 | 4CPU/6G | Manager |
为验证后续的 swarm manager 高可用,将这三台节点都配置成为 Manager 节点。
3.2 前置准备
3.2.1 修改主机名
hostnamectl --static --transient set-hostname swarm01
修改 /etc/hosts 。三台主机上均设置一致.
[root@swarm01 ~]# cat /etc/hosts
127.0.0.1 swarm-manager localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
172.21.111.56 swarm01
172.21.111.57 swarm02
172.21.111.58 swarm03
3.2.2 配置互信
ssh-keygen -t rsa
ssh-copy-id -i .ssh/id_rsa.pub 172.21.111.57
3.2.3 关闭防火墙和 SELinux
systemctl disable firewalld
systemctl stop firewalld
修改 /etc/selinux/config ,修改配置项 SELINUX=enforcing为disabled。
3.2 安装 Docker 服务
如前文所示,从 v1.12 开始,Docker Swarm 的功能已经完全与 Docker Engine 集成,要管理集群,只需要启动 Swarm Mode。安装好 Docker,Swarm 就已经在那里了,服务发现也在那里了(不需要安装 Consul 等外部数据库)。配置好 yum 源之后,即可安装 docker-ce。
yum install -y docker-ce
systemctl enable docker
systemctl start docker
3.3 集群初始化
3.2.1 初始化主节点
使用命令 docker swarm init 即可初始化当前节点为主节点。如果主机上有多张网卡的时候,需指定网卡 docker swarm init --advertise-addr [IP] --listen-addr [IP:PORT]
节点自动解锁: docker swarm init –autolock=false
[root@swarm01 ~]# docker swarm init --autolock=false --advertise-addr 172.21.111.56 --listen-addr 172.21.111.56:2377
Swarm initialized: current node (epoic1y0vv830vnwbc6nnacjc) is now a manager.
To add a worker to this swarm, run the following command:
docker swarm join --token SWMTKN-1-5t9jv2o6z3ep9mk5c2ae41bpqojla1g8cfjo3qlsuj2sxi934l-af2x3lh8vs6dnpepy66kdw5mv 172.21.111.56:2377
To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.
此例,在 swarm01 中创建了主节点。从输出中,看到添加集群有两种方式,一种是以 manager 的方式添加,一种则是以 worker 节点方式添加。默认输出只给出了添加 worker 的命令,manager 命令则需要通过 docker swarm join-token manager 获取。
[root@swarm01 ~]# docker swarm join-token manager
To add a manager to this swarm, run the following command:
docker swarm join --token SWMTKN-1-5t9jv2o6z3ep9mk5c2ae41bpqojla1g8cfjo3qlsuj2sxi934l-eszh52z00ktao9j7lovfvjgqy 172.21.111.56:2377
3.2.2 添加 manager 节点
分别登陆 swarm02、swarm03,执行上一节得到的命令。
[root@swarm03 ~]#docker swarm join --token SWMTKN-1-5t9jv2o6z3ep9mk5c2ae41bpqojla1g8cfjo3qlsuj2sxi934l-eszh52z00ktao9j7lovfvjgqy 172.21.111.56:2377
This node joined a swarm as a manager.
注:不要在节点上配置 http 代理,否则会添加节点失败。
3.2.3 离开集群
如果想退出集群,可以在该节点上直接退出。
[root@swarm03 ~]# docker swarm leave
[root@swarm03 ~]# docker swarm leave --force
3.2.4 查看集群节点信息
登陆任意一台 Manager 节点。都可以查看当前集群的节点信息。
[root@swarm02 ~]# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
epoic1y0vv830vnwbc6nnacjc swarm01 Ready Active Leader 18.03.1-ce
nsqqv181e0r7mu77azixtqhzl * swarm02 Ready Active Reachable 18.03.1-ce
mkkxaeqergz8xw21bbkd47q1c swarm03 Ready Active Reachable 18.03.1-ce
上面信息中,AVAILABILITY 表示 Swarm Scheduler 是否可以向集群中的某个 Node 指派 Task,对应有如下三种状态:
- Active:集群中该 Node 可以被指派 Task
- Pause:集群中该 Node 不可以被指派新的 Task,但是其他已经存在的 Task 保持运行
- Drain:集群中该 Node 不可以被指派新的 Task,Swarm Scheduler 停掉已经存在的 Task,并将它们调度到可用的 Node 上
另外,可以看到 Manager Status 状态也有分类,分别是 Leader、Reacheable、Unreachable。
- Leader:对应 Raft 算法的 Leader 节点
- Reacheable:对应 Raft 算法的 Flower 节点,网络可达、可用的 Flower 节点
- Unreachable:对应 Raft 算法的 Flower 节点,网络不可达、不可用的 Flower 节点
查看单个节点详细信息
[root@swarm02 ~]# docker node inspect swarm01
关于 Node 的其他操作,比如状态变更、添加标签、提权和降权等,详见附录2
四、高可用实践
4.1 应用服务管理
docker swarm 还可以使用 stack 这一模型,用来部署管理和关联不同的服务。stack 功能比 service 还要强大,因为它具备多服务编排部署的能力。stack file 是一种 yaml 格式的文件,类似于 docker-compose.yml 文件,它定义了一个或多个服务,并定义了服务的环境变量、部署标签、容器数量以及相关的环境特定配置等。
以下实验仅仅创建利用 stack 创建单一服务。
4.1.1 创建服务
服务配置文件 docker-swarm.yml ,内容如下
version: '3'
services:
web:
image: "httpd:v1"
deploy:
replicas: 3
resources:
limits:
cpus: "0.5"
memory: 256M
restart_policy:
condition: on-failure
ports:
- "7080:80"
volumes:
- /var/www/html:/usr/local/apache2/htdocs
image: “httpd” :httpd 是 docker hub 下载的镜像。提供简单的 httpd 服务,此处用来做服务都高可用验证。
replicas: 3 表示该服务副本有 3 个,可对服务副本进行扩缩容,后续会讲到。
/var/www/html:/usr/local/apache2/htdocs :表示 httpd 首页的内容。各个 swarm 节点上展示的内容分别是其主机名信息。
在 docker-swarm.yml 同级目录下,执行命令
[root@swarm01 swarm]# docker stack deploy -c docker-swarm.yml myservice
Creating network myservice_default
Creating service myservice_web
4.1.2 查看服务
查看服务创建是否成功。
[root@swarm01 swarm]# docker stack ls
NAME SERVICES
myservice 1
[root@swarm01 swarm]# docker stack services myservice
ID NAME MODE REPLICAS IMAGE PORTS
kom8x49f7qv2 myservice_web replicated 3/3 httpd:latest *:7080->80/tcp
[root@swarm01 swarm]# docker stack ps myservice
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
sybn1dur1wmw myservice_web.1 httpd:latest swarm03 Running Running 45 seconds ago
mlcb5r9vzv6z myservice_web.2 httpd:latest swarm03 Running Running 45 seconds ago
fw21lcu3zp83 myservice_web.3 httpd:latest swarm01 Running Running 45 seconds ago
可以看到 swarm01 上面运行了1个容器,swarm03 上面运行了 2个,而 swarm02 上面一个容器都没有,这是咋回事呢?哦,原来我们在创建集群过程中,对 swarm02 做了状态变更的操作。docker node update –availability drain swarm02. 查看集群状态。
[root@swarm01 swarm]# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
epoic1y0vv830vnwbc6nnacjc * swarm01 Ready Active Leader 18.03.1-ce
nsqqv181e0r7mu77azixtqhzl swarm02 Ready Drain Reachable 18.03.1-ce
mkkxaeqergz8xw21bbkd47q1c swarm03 Ready Active Reachable 18.03.1-ce
此时打开浏览器,输入 HTTP URL。任意 swarm 集群节点都可以访问 httpd 服务。
需要说明的是,由于3个节点的 /var/www/html 路径未做共享存储。因此 swarm 会随机显示一个 swarm 节点的网页内容。
4.1.3 服务扩缩容
修改 docker-swarm.yml 配置字段 replicas: 5 ,将容器个数提升到5个。由于实验环境资源有限,因此这里将 swarm02 状态变更为可以状态,用以分配容器。
docker node update --availability active swarm02.
重新执行部署命令: docker stack deploy -c docker-swarm.yml myservice
也可以通过命令直接对服务进行操作,但是不推荐。 docker service scale 服务 ID= 服务个数
[root@swarm01 swarm]# docker stack ps myservice
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
unwepav5z9nz myservice_web.1 httpd:v1 swarm02 Running Running less than a second ago
3j5o1tktcg1l myservice_web.2 httpd:v1 swarm01 Running Preparing 3 seconds ago
wl1unt6lynft myservice_web.3 httpd:v1 swarm03 Running Running less than a second ago
[root@swarm01 swarm]# vi docker-swarm.yml
[root@swarm01 swarm]# docker stack deploy -c docker-swarm.yml myservice
Updating service myservice_web (id: 85quzwi5k0btkn5wlht4jbco9)
image httpd:v1 could not be accessed on a registry to record
its digest. Each node will access httpd:v1 independently,
possibly leading to different nodes running different
versions of the image.
[root@swarm01 swarm]# docker stack ps myservice
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
unwepav5z9nz myservice_web.1 httpd:v1 swarm02 Running Running 24 seconds ago
3j5o1tktcg1l myservice_web.2 httpd:v1 swarm01 Running Running 31 seconds ago
wl1unt6lynft myservice_web.3 httpd:v1 swarm03 Running Running 24 seconds ago
ujedjxbuffxp myservice_web.4 httpd:v1 swarm01 Running Running less than a second ago
ml9qvjh2add7 myservice_web.5 httpd:v1 swarm02 Running Running less than a second ago
同样,对于服务缩容,也仅需要修改 replicas: 配置即可。这里不再演示。
4.1.4 删除服务
例如,删除 myredis 应用服务,执行 docker service rm myredis,则应用服务 myredis 的全部副本都会被删除。
本例使用的是 stack ,删除 stack ,即可删除其下的服务。没错,docker 语法非常类似, docker stack rm myservice。
需要注意的是,对 swarm 上面服务的操作,都必须在 manager 节点上运行。
4.1.5 服务升降级
服务升降级,对应到 docker 中,则利用了容器镜像的更新,升级很好理解,直接把 tag 标签版本往上提。那么降级,其实也可以理解为另外一种“升级“,只是镜像内容是上一个版本的而已。对于镜像标签的命令应该遵循一套严格的规范,这里不再赘述。
先介绍利用 service 命令行工具的用法。
服务的滚动更新,这里我参考官网文档的例子说明。在 Manager Node 上执行如下命令:
docker service create --replicas 3 --name redis --update-delay 10s redis:3.0.6
上面通过指定 –update-delay 选项,表示需要进行更新的服务,每次成功部署一个,延迟10秒钟,然后再更新下一个服务。如果某个服务更新失败,则 Swarm 的调度器就会暂停本次服务的部署更新。
另外,也可以更新已经部署的服务所在容器中使用的 Image 的版本,例如执行如下命令:
将 Redis 服务对应的 Image 版本有 3.0.6 更新为 3.0.7,同样,如果更新失败,则暂停本次更新。
那么,stack file 如何定义滚动更新呢?
update_config:
parallelism: 2
delay: 10s
修改docker-swarm.yml 如下
version: '3'
services:
web:
image: "httpd:v2"
deploy:
replicas: 3
update_config:
parallelism: 2
delay: 30s
resources:
limits:
cpus: "0.5"
memory: 256M
restart_policy:
condition: on-failure
ports:
- "7080:80"
volumes:
- /var/www/html:/usr/local/apache2/htdocs
parallelism 表示同时升级的个数,delay 则表示间隔多长时间升级。
同时将 httpd 由 v1 升级到 v2,这里我们使用同一个镜像,只是 tag 修改了一下。查看服务状态
[root@swarm01 swarm]# docker stack ps myservice
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
qk8pvvc9nmv0 myservice_web.1 httpd:v2 swarm01 Running Running 56 seconds ago
unwepav5z9nz \_ myservice_web.1 httpd:v1 swarm02 Shutdown Shutdown 48 seconds ago
uyj0pm1df9hl myservice_web.2 httpd:v2 swarm02 Running Running 46 seconds ago
3j5o1tktcg1l \_ myservice_web.2 httpd:v1 swarm01 Shutdown Shutdown about a minute ago
qdjov5zf5alb myservice_web.3 httpd:v2 swarm03 Running Running 10 seconds ago
wl1unt6lynft \_ myservice_web.3 httpd:v1 swarm03 Shutdown Shutdown 12 seconds ago
可以看到同时只有 2 个容器在升级,同时第3个容器也是在间隔了 30s 之后,才开始升级。
–filter 过滤条件 docker stack ps –filter “desired-state=running” myservice
4.2 应用服务高可用
书接上文。在前面创建的 myservice 的基础上,进行容器应用的高可用验证。
4.2.1 模拟容器故障
查看当前服务状态
[root@swarm01 swarm]# docker stack ps --filter "desired-state=running" myservice
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
qk8pvvc9nmv0 myservice_web.1 httpd:v2 swarm01 Running Running 16 minutes ago
uyj0pm1df9hl myservice_web.2 httpd:v2 swarm02 Running Running 16 minutes ago
qdjov5zf5alb myservice_web.3 httpd:v2 swarm03 Running Running 15 minutes ago
swarm01-03 分别运行3个容器。现在登陆 swam03 节点,将其容器进程 Kill 掉。模拟容器意外故障。
将 stack ps 得到的 swarm03 节点的 ID qdjov5zf5alb 代入命令 inspect。
[root@swarm01 swarm]# docker inspect qdjov5zf5alb
[
{
"ID": "qdjov5zf5albdm1o7vhuwoxjt",
...
"Spec": {
"ContainerSpec": {
"Image": "httpd:v2",
"Labels": {
"com.docker.stack.namespace": "myservice"
},
"Privileges": {
"CredentialSpec": null,
"SELinuxContext": null
},
"Mounts": [
{
"Type": "bind",
"Source": "/var/www/html",
"Target": "/usr/local/apache2/htdocs"
}
],
"Isolation": "default"
},
"Resources": {
"Limits": {
"NanoCPUs": 500000000,
"MemoryBytes": 268435456
}
},
....
"ServiceID": "85quzwi5k0btkn5wlht4jbco9",
"Slot": 3,
"NodeID": "mkkxaeqergz8xw21bbkd47q1c",
"Status": {
"Timestamp": "2018-08-07T09:02:25.674376822Z",
"State": "running",
"Message": "started",
"ContainerStatus": {
"ContainerID": "fa7d228e0c1981bfc78bca0b81363d7ca44cac99844c2996afe528ae3ae9a129",
"PID": 8852,
"ExitCode": 0
},
"PortStatus": {}
},
得到得到其对于的容器 fa7d228e0c1981bfc78bca0b81363d7ca44cac99844c2996afe528ae3ae9a129 (swarm03 节点上运行)
登陆 swarm03 节点,查看容器 fa7d22 对应的进程。得到其进程号,并将其杀死。
[root@swarm03 /]# ps -ef|grep fa7d228e0c19
root 8832 1129 0 05:02 ? 00:00:00 docker-containerd-shim -namespace moby -workdir /var/lib/docker/containerd/daemon/io.containerd.runtime.v1.linux/moby/fa7d228e0c1981bfc78bca0b81363d7ca44cac99844c2996afe528ae3ae9a129 -address /var/run/docker/containerd/docker-containerd.sock -containerd-binary /usr/bin/docker-containerd -runtime-root /var/run/docker/runtime-runc
root 9989 1090 0 05:32 pts/0 00:00:00 grep --color=auto fa7d228e0c19
[root@swarm03 /]# kill -9 8832
4.2.2 故障查看
立即查看服务状态。
[root@swarm03 /]# docker stack ps myservice
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
qk8pvvc9nmv0 myservice_web.1 httpd:v2 swarm01 Running Running 32 minutes ago
unwepav5z9nz \_ myservice_web.1 httpd:v1 swarm02 Shutdown Shutdown 32 minutes ago
uyj0pm1df9hl myservice_web.2 httpd:v2 swarm02 Running Running 32 minutes ago
3j5o1tktcg1l \_ myservice_web.2 httpd:v1 swarm01 Shutdown Shutdown 32 minutes ago
hx741f0kye5a myservice_web.3 httpd:v2 swarm03 Running Running 29 seconds ago
qdjov5zf5alb \_ myservice_web.3 httpd:v2 swarm03 Shutdown Failed 36 seconds ago "task: non-zero exit (137)"
wl1unt6lynft \_ myservice_web.3 httpd:v1 swarm03 Shutdown Shutdown 31 minutes ago
可以看到,swarm03 上面的容器 myservice_web.3 立即被重启。故障即刻恢复。
4.2.3 结论
通过以上实验我们得出,在 docker swarm 集群服务中,任意容器出现故障意外死亡,都会被重启。满足应用服务高可用的需求。但是,可能会有同学有疑问,你这个只是 kill 掉进程,模拟的是进程级别的故障,如果是主机宕机呢,swarm 是否也能满足呢?答案是肯定的!
在下一个章节,就让我们继续模拟主机级别的故障,验证服务的高可用。同时,由于我们环境配置的均是 Manager 节点,我们也可以同时验证 Swarm Manager 的高可用。让我们拭目以待吧!
4.3 Swarm Manager 高可用
查看当前 swarm 集群节点信息
[root@swarm01 swarm]# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
epoic1y0vv830vnwbc6nnacjc * swarm01 Ready Active Leader 18.03.1-ce
nsqqv181e0r7mu77azixtqhzl swarm02 Ready Active Reachable 18.03.1-ce
mkkxaeqergz8xw21bbkd47q1c swarm03 Ready Active Reachable 18.03.1-ce
以上可知,swarm01 为 swarm 集群管理节点。倘若 swarm01 突然宕机关机会怎样呢,整个 swarm 集群会失效,陷入瘫痪吗?其上运行的容器服务是否会全部挂掉,无法继续提供服务?
4.3.1 模拟主机宕机
将虚拟机 swarm01 直接关机。
4.3.2 故障查看
登陆 swarm03 ,查看 swarm 集群状态。
[root@swarm03 /]# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
epoic1y0vv830vnwbc6nnacjc swarm01 Unknown Active Unreachable 18.03.1-ce
nsqqv181e0r7mu77azixtqhzl swarm02 Ready Active Reachable 18.03.1-ce
mkkxaeqergz8xw21bbkd47q1c * swarm03 Ready Active Leader 18.03.1-ce
在经历短暂的间隙后,可看到 swarm 集群认定 swarm01 现在处于 Unknown 状态,MANAGER STATUS 处于 Unreachable 状态。同时,swarm 集群基于 raft 算法,重新推举出新的 Leader swarm03。
再过一段时间,swarm01 状态变成 Down
[root@swarm03 ~]# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
epoic1y0vv830vnwbc6nnacjc swarm01 Down Active Unreachable 18.03.1-ce
nsqqv181e0r7mu77azixtqhzl swarm02 Ready Active Reachable 18.03.1-ce
mkkxaeqergz8xw21bbkd47q1c * swarm03 Ready Active Leader 18.03.1-ce
查看服务状态
[root@swarm03 /]# docker stack ps myservice
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
zfbvcz5iu8g7 myservice_web.1 httpd:v2 swarm03 Running Running 2 minutes ago
qk8pvvc9nmv0 \_ myservice_web.1 httpd:v2 swarm01 Shutdown Running about an hour ago
unwepav5z9nz \_ myservice_web.1 httpd:v1 swarm02 Shutdown Shutdown about an hour ago
uyj0pm1df9hl myservice_web.2 httpd:v2 swarm02 Running Running 3 minutes ago
3j5o1tktcg1l \_ myservice_web.2 httpd:v1 swarm01 Shutdown Shutdown about an hour ago
hx741f0kye5a myservice_web.3 httpd:v2 swarm03 Running Running 3 minutes ago
qdjov5zf5alb \_ myservice_web.3 httpd:v2 swarm03 Shutdown Failed 21 minutes ago "task: non-zero exit (137)"
wl1unt6lynft \_ myservice_web.3 httpd:v1 swarm03 Shutdown Shutdown about an hour ago
可以看到容器服务个数依然维持在3个,原先在 swarm01 上面运行的容器,被分配到 swarm02 和 swarm03 上面。现在对服务进行扩容操作,以验证此时 swarm 集群是否对服务还有管理能力。
[root@swarm03 swarm]# docker stack deploy -c docker-swarm.yml myservice
Updating service myservice_web (id: 85quzwi5k0btkn5wlht4jbco9)
image httpd:v2 could not be accessed on a registry to record
its digest. Each node will access httpd:v2 independently,
possibly leading to different nodes running different
versions of the image.
[root@swarm03 swarm]# docker stack ps myservice
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
zfbvcz5iu8g7 myservice_web.1 httpd:v2 swarm03 Running Running 6 minutes ago
qk8pvvc9nmv0 \_ myservice_web.1 httpd:v2 swarm01 Shutdown Running about an hour ago
unwepav5z9nz \_ myservice_web.1 httpd:v1 swarm02 Shutdown Shutdown about an hour ago
uyj0pm1df9hl myservice_web.2 httpd:v2 swarm02 Running Running 6 minutes ago
3j5o1tktcg1l \_ myservice_web.2 httpd:v1 swarm01 Shutdown Shutdown about an hour ago
hx741f0kye5a myservice_web.3 httpd:v2 swarm03 Running Running 6 minutes ago
qdjov5zf5alb \_ myservice_web.3 httpd:v2 swarm03 Shutdown Failed 25 minutes ago "task: non-zero exit (137)"
wl1unt6lynft \_ myservice_web.3 httpd:v1 swarm03 Shutdown Shutdown about an hour ago
6nifzsbysug5 myservice_web.4 httpd:v2 swarm02 Running Running 20 seconds ago
uwgnl2usv59a myservice_web.5 httpd:v2 swarm02 Running Running 20 seconds ago
可以看到,此时 swarm 集群依然具有管理能力(服务扩容能力)。也从侧面验证 swarm manager 的高可用能力。
此时重启 swarm01 ,看看 swarm01 节点是否会自动加入集群。
登陆 swarm01 ,查看集群状态
[root@swarm01 ~]# docker node ls
Error response from daemon: Swarm is encrypted and needs to be unlocked before it can be used. Please use "docker swarm unlock" to unlock it.
可以看到,此时 swarm01 处于被锁的状态。需要解锁。
[root@swarm01 ~]# docker swarm unlock
Please enter unlock key:
Error response from daemon: invalid key string
那么 unlock key 从哪里取值呢?答案就是,需要在可用的集群管理节点,比如 swarm03 上面执行命令
[root@swarm03 ~]# docker swarm unlock-key
To unlock a swarm manager after it restarts, run the `docker swarm unlock`
command and provide the following key:
SWMKEY-1-796L7+nU55V/qGCMPgBvKS/5PyotvNaKPS4SJ0AUe+g
Please remember to store this key in a password manager, since without it you
will not be able to restart the manager.
通过该 unlock key : SWMKEY-1-796L7+nU55V/qGCMPgBvKS/5PyotvNaKPS4SJ0AUe+g ,重新加入集群。
此时在 swarm01 上面查看集群状态,即可看到已经重新加入集群。
[root@swarm01 ~]# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
epoic1y0vv830vnwbc6nnacjc * swarm01 Ready Active Reachable 18.03.1-ce
nsqqv181e0r7mu77azixtqhzl swarm02 Ready Active Reachable 18.03.1-ce
mkkxaeqergz8xw21bbkd47q1c swarm03 Ready Active Leader 18.03.1-ce
但是如果再把 swarm03 关掉,即同时宕掉2个节点,则此时3个管理节点,只剩下一个节点,不满足 Raft 协议的节点个数要求(>N/2),集群功能就会失效,不能再管理集群,但是集群上的服务还能够继续运行。
继续我们的脚步,将 swarm03,swarm01 都关机。
登陆 swarm02,查看集群状态
[root@swarm02 ~]# docker node ls
Error response from daemon: rpc error: code = Unknown desc = The swarm does not have a leader. It's possible that too few managers are online. Make sure more than half of the managers are online.
[root@swarm02 ~]# docker stack ps myservice
Error response from daemon: rpc error: code = Unknown desc = The swarm does not have a leader. It's possible that too few managers are online. Make sure more than half of the managers are online.
可以看到,此时集群功能已经失效,不能通过 swarm 命令查看集群和管理集群了。那么运行其上的任务呢?
[root@swarm02 ~]# docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
2cc1b76be2cf httpd:v2 "httpd-foreground" 2 hours ago Up 2 hours 80/tcp myservice_web.5.uwgnl2usv59aygb5e9a8cig2y
96034bff8902 httpd:v2 "httpd-foreground" 2 hours ago Up 2 hours 80/tcp myservice_web.4.6nifzsbysug5medburznrrr7h
82beb10e4cac httpd:v2 "httpd-foreground" 3 hours ago Up 3 hours 80/tcp myservice_web.2.uyj0pm1df9hlx9vdvck36ilbl
ea9f879cdf12 composetest_web:v1 "python app.py" 3 weeks ago Up 5 hours 0.0.0.0:5000->5000/tcp elegant_borg
还好还好,通过 docker container ls 查看swarm02节点上的容器,可以看到仍然有3个容器在运行,这些都是之前已经分配好的。显然,swarm 集群即使失效了,也不会影响其上运行的容器服务正常运行,只是失去了管理和调度的能力了。
此时,如果再次打开 swarm01 和 swarm03 的电源,他们会重新组建集群吗?从上文中我们知道,离线的 manager节点要重新加入集群需要解锁,而钥匙需要通过原集群运行 docker swarm unlock-key 获取。那么显然,原集群已经失效了。那此时会怎样呢?
不幸的是,确实 swarm01 和 swarm03 都无法自动加入集群,确实需要通过 docker swarm unlock 进行解锁。但是幸运的是,unlock key 是不变的,跟刚才 swarm01 宕机时重新加入的 key 是一样的。分别在 swarm01 和swarm03 执行解锁操作。集群最终恢复正常。因此需要在创建集群后,第一时间保存 unlock key 。
[root@swarm03 ~]# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
epoic1y0vv830vnwbc6nnacjc swarm01 Ready Active Reachable 18.03.1-ce
nsqqv181e0r7mu77azixtqhzl swarm02 Ready Active Leader 18.03.1-ce
mkkxaeqergz8xw21bbkd47q1c * swarm03 Ready Active Reachable 18.03.1-ce
注:在创建集群的时候,可设置自动解锁,即主机重启时,不用输入密钥,即可重新加入集群
docker swarm init --autolock=false
docker swarm update --autolock=false
4.3.3 结论
从以上实验中也可以看出,只要管理节点正常,服务的高可用就能达到,但是管理节点的个数必须保持在总的管理节点个数的一半以上,即3个只允许宕机一台,5台只允许宕机2台。而总的管理节点的个数一般不超过7个,如果太多的话,集群内管理节点通信消耗会比较大。由于偶数性价比不高(因为4台也只能宕机掉1台跟3台时是一样的),所以管理节点的个数一般都是奇数。
管理节点的个数以及允许宕机的个数如下:
| mannager node | 允许宕机个数 | 服务运行状态 |
|---|---|---|
| 3 | 1 | 正常 |
| 5 | 2 | 正常 |
| 7 | 3 | 正常 |
4.4 网络故障转移
4.4.1 模拟网络分区
环境说明:仍然是3台虚拟机组成的 swarm 管理集群
hd_hd-1 服务:运行4个副本,分别 swarm01/swarm02 各一个容器,swarm03 运行2个容器
将 swarm02 网卡拔掉,模拟网络故障分区。
备注使用 –autolock=false 初始化集群:docker swarm init –autolock=false –advertise-addr 172.21.111.56 –listen-addr 172.21.111.56:2377
###4.4.2 观察 swarm node 信息
查看集群信息和服务状态
[root@swarm01 httpd]# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
wk8jaypu23vr63082arpsl4ut * swarm01 Ready Active Leader 18.03.1-ce
q9lcw91vus73wyly174iy72h3 swarm02 Down Active Unreachable 18.03.1-ce
1xelzfyr5kbn7kk70le45anei swarm03 Ready Active Reachable 18.06.1-ce
[root@swarm01 httpd]# docker service ps hd_hd-1
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
t604bqtcj588 hd_hd-1.1 httpd:latest swarm01 Running Running 2 minutes ago
xfajbfz51nd9 \_ hd_hd-1.1 httpd:latest swarm02 Shutdown Running 8 minutes ago
8clt10jl1xyf hd_hd-1.2 httpd:latest swarm01 Running Running 6 minutes ago
py5cavsog5mo hd_hd-1.3 httpd:latest swarm03 Running Running 7 minutes ago
oigopryy1kro hd_hd-1.4 httpd:latest swarm03 Running Running 7 minutes ago
我们可以发现,集群认为 swarm02 现在已经失联(不论是宕机还是网络端开)。现在 swarm02 上面的容器被迁移到 swarm01 上面(调度策略应该是 swarm01 上面目前运行的容器个数比 swarm03 少)。
通过虚拟机控制台登陆 swarm02,验证集群功能和容器是否在运行

我们可以发现,swarm02 由于当前是一个节点,根据 raft 算法,处于 swarm 集群功能不可用状态。docker ps 查看容器,发现容器仍然在正常运行。得出结论,swarm 集群功能失效,但是不影响原先已经运行的 docker 容器。
综合 swarm01/swarm03 上面的容器个数和 swarm02 上面的容器个数,现在已经有5个容器了。而我们预设的容器个数是4个。那么当 swarm02 重新加入集群,会发生什么事情呢?
4.4.3 网络故障恢复
把 swarm02 网卡重新接上。swarm02 会自动加入集群。查看集群信息和服务信息。
[root@swarm01 httpd]# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
lkivi02vx5z939z0x7lacuarl * swarm01 Ready Active Leader 18.03.1-ce
pdp0awtf34o4x60x812h07a6e swarm02 Ready Active Reachable 18.03.1-ce
qavrh9e6pjdq2aoxpucl6nohm swarm03 Ready Active Reachable 18.06.1-ce
[root@swarm01 httpd]# docker service ps hd_hd-1
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
pepxi7bmzi8r hd_hd-1.1 httpd:latest swarm01 Running Running 2 minutes ago
yf42dr6fqvl5 \_ hd_hd-1.1 httpd:latest swarm02 Shutdown Shutdown 2 minutes ago
j6iq7tpsnwb0 hd_hd-1.2 httpd:latest swarm03 Running Running 2 minutes ago
k23a3ezbocit hd_hd-1.3 httpd:latest swarm03 Running Running 2 minutes ago
bqra1k9m0ojc hd_hd-1.4 httpd:latest swarm01 Running Running 2 minutes ago
我们发现 swarm02 已经正常加入集群。登陆 swarm02,查看 swarm02 上面原先的容器也已经停掉了。符合我们的预期。

五、附录
5.1参考文章:
docker swarm 介绍:
- http://shiyanjun.cn/archives/1625.html
- https://jiayi.space/post/docker-swarmrong-qi-ji-qun-guan-li-gong-ju
- http://www.shangyang.me/2018/02/01/docker-swarm-03-architect/
- http://blog.51cto.com/cloudman/1952873
- https://www.cnblogs.com/bigberg/p/8761047.html
- 服务发现:https://success.docker.com/article/ucp-service-discovery
- raft协议:http://thesecretlivesofdata.com/raft/
5.2 Swarm Node 节点操作
5.2.1 状态变更
前面我们已经提到过,Node 的 AVAILABILITY 有三种状态:Active、Pause、Drain,对某个 Node 进行变更,可以将其 AVAILABILITY 值通过 Docker CLI 修改为对应的状态即可,下面是常见的变更操作:
- 设置 Manager Node 只具有管理功能
- 对服务进行停机维护,可以修改 AVAILABILITY 为 Drain 状态
- 暂停一个 Node,然后该 Node 就不再接收新的 Task
- 恢复一个不可用或者暂停的 Node
例如,将 Manager Node 的 AVAILABILITY 值修改为 Drain 状态,使其只具备管理功能,执行如下命令:
[root@swarm02 ~]# docker node update --availability drain swarm02
swarm02
[root@swarm02 ~]# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
epoic1y0vv830vnwbc6nnacjc swarm01 Ready Active Leader 18.03.1-ce
nsqqv181e0r7mu77azixtqhzl * swarm02 Ready Drain Reachable 18.03.1-ce
mkkxaeqergz8xw21bbkd47q1c swarm03 Ready Active Reachable 18.03.1-ce
这样,Manager Node 不能被指派 Task,也就是不能部署实际的 Docker 容器来运行服务,而只是作为管理 Node 的角色。
5.2.2 添加标签
每个 Node 的主机配置情况可能不同,比如有的适合运行 CPU 密集型应用,有的适合运行 IO 密集型应用,Swarm 支持给每个 Node 添加标签元数据,这样可以根据 Node 的标签,来选择性地调度某个服务部署到期望的一组 Node 上。 给 SWarm 集群中的某个 Worker Node 添加标签,执行如下命令格式如下:
[root@swarm02 ~]# docker node update --label-add app=dev swarm02
swarm02
5.2.3 提权/降权
改变 Node 的角色,Worker Node 可以变为 Manager Node,这样实际 Worker Node 有工作 Node 变成了管理 Node,对应操作分别是:
docker node promote swarm02
docker node demote swarm02
5.3 网络管理
5.3.1 添加 overlay 网络
overlay 网络是 swarm 中默认的跨主机网络模型。在 Swarm 集群中可以使用 Overlay 网络来连接到一个或多个服务。具体添加 Overlay 网络,首先,我们需要创建在 Manager Node 上创建一个Overlay 网络,执行如下命令:
docker network create --driver overlay my-network
创建完 Overlay 网络 my-network 以后,Swarm 集群中所有的 Manager Node 都可以访问该网络。然后,我们在创建服务的时候,只需要指定使用的网络为已存在的 Overlay 网络即可,如下命令所示:
docker service create --replicas 3 --network my-network --name myweb nginx
这样,如果 Swarm 集群中其他 Node 上的 Docker 容器也使用 my-network 这个网络,那么处于该 Overlay 网络中的所有容器之间,通过网络可以连通。
5.4 API
$ curl --unix-socket /var/run/docker.sock -H "Content-Type: application/json" \
-d '{"Image": "alpine", "Cmd": ["echo", "hello world"]}' \
-X POST http:/v1.24/containers/create
{"Id":"1c6594faf5","Warnings":null}
$ curl --unix-socket /var/run/docker.sock -X POST http:/v1.24/containers/1c6594faf5/start
$ curl --unix-socket /var/run/docker.sock -X POST http:/v1.24/containers/1c6594faf5/wait
{"StatusCode":0}
$ curl --unix-socket /var/run/docker.sock "http:/v1.24/containers/1c6594faf5/logs?stdout=1"
hello world
https://docs.docker.com/develop/sdk/#sdk-and-api-quickstart
https://docs.docker.com/develop/sdk/#sdk-and-api-quickstart
5.5 Docker 三剑客
- docker-compose 负责组织应用,应用由哪些服务组成,每个服务由多少个容器,均在该配置文件里面配置。
- docker-machine 负责提供虚拟机,该虚拟机具备 docker daemon 服务能力。创建的虚拟机,可以用来组成 docker swarm 集群。docker-machine 并不是必须的功能。完全可以手动安装 docker 服务。
- docker swarm 负责组织 docker 集群,组织跨主机的 docker 集群管理能力。
原文链接:http://zhoujinl.github.io/2018/10/19/docker-swarm-manager-ha/#&gid=1&pid=16